Démarche & Architecture
Objectif du projet
L’objectif de ce projet est de construire une plateforme complète de collecte, stockage, traitement et visualisation de données de marché autour du Bitcoin. L’idée n’est pas seulement d’afficher des graphiques, mais de mettre en place une logique cohérente de pipeline data, proche de celle que l’on peut retrouver dans un environnement technique réel.
Le projet relie ainsi plusieurs dimensions complémentaires : récupération automatisée de données, modélisation en base PostgreSQL, création d’une API, développement d’un site web d’analyse et supervision du serveur sur lequel tourne l’ensemble.
Pourquoi ce projet ?
Ce projet est né de la volonté de construire un système complet autour de la donnée, depuis la collecte jusqu’à la visualisation. Le Bitcoin constitue un support pertinent car il génère des données fréquentes, réelles et directement exploitables pour produire des indicateurs de marché.
Il permet aussi de relier plusieurs compétences : data engineering, structuration de base de données, création d’API, développement web et analyse de données sur des séries temporelles.
Méthode de construction
Le site a été construit progressivement, en ajoutant les briques une par une : ingestion des données, stockage en base, exposition via API, création des dashboards puis ajout du monitoring serveur.
Cette approche progressive a permis de vérifier chaque étape séparément, puis d’optimiser le fonctionnement global au fur et à mesure de l’avancement.
Problème majeur rencontré
Le principal problème rencontré a concerné le temps de chargement des pages, notamment lorsque plusieurs graphiques et indicateurs étaient demandés simultanément. Cela alourdissait la page principale et nuisait à la fluidité globale du site.
Pour corriger cela, le chargement a été séparé en plusieurs étapes : la vue principale de la page BTC est chargée en priorité, puis les éléments d’analyse plus avancés sont récupérés ensuite. Cette séparation permet de conserver un site plus réactif sans supprimer les indicateurs secondaires.
Architecture générale
Le projet repose sur un VPS Ubuntu qui constitue l’environnement principal d’exécution. C’est cette machine qui héberge toutes les briques nécessaires au fonctionnement du site, de la base de données et du monitoring.
À l’intérieur de ce VPS, Docker permet d’exécuter et de séparer les différents services du projet. Cela évite que tout soit mélangé dans le même environnement et rend l’architecture plus lisible, plus stable et plus simple à maintenir.
Lecture du schéma
Le schéma ne représente pas des blocs indépendants, mais une chaîne logique. Ubuntu constitue la machine hôte, Docker exécute les services, Python réalise l’ingestion des données depuis Internet, PostgreSQL stocke les données, FastAPI les expose au site web, puis le dashboard affiche les graphiques finaux.
En parallèle, Prometheus collecte les métriques techniques du système et des services, puis Grafana permet de les visualiser pour suivre l’état du serveur. Le site et la partie monitoring partagent donc une même infrastructure, mais répondent à deux usages différents : analyse de marché et supervision technique.
Schéma serveur
Le schéma ci-dessous présente une vue simplifiée des principaux composants et de leurs interactions dans la plateforme.
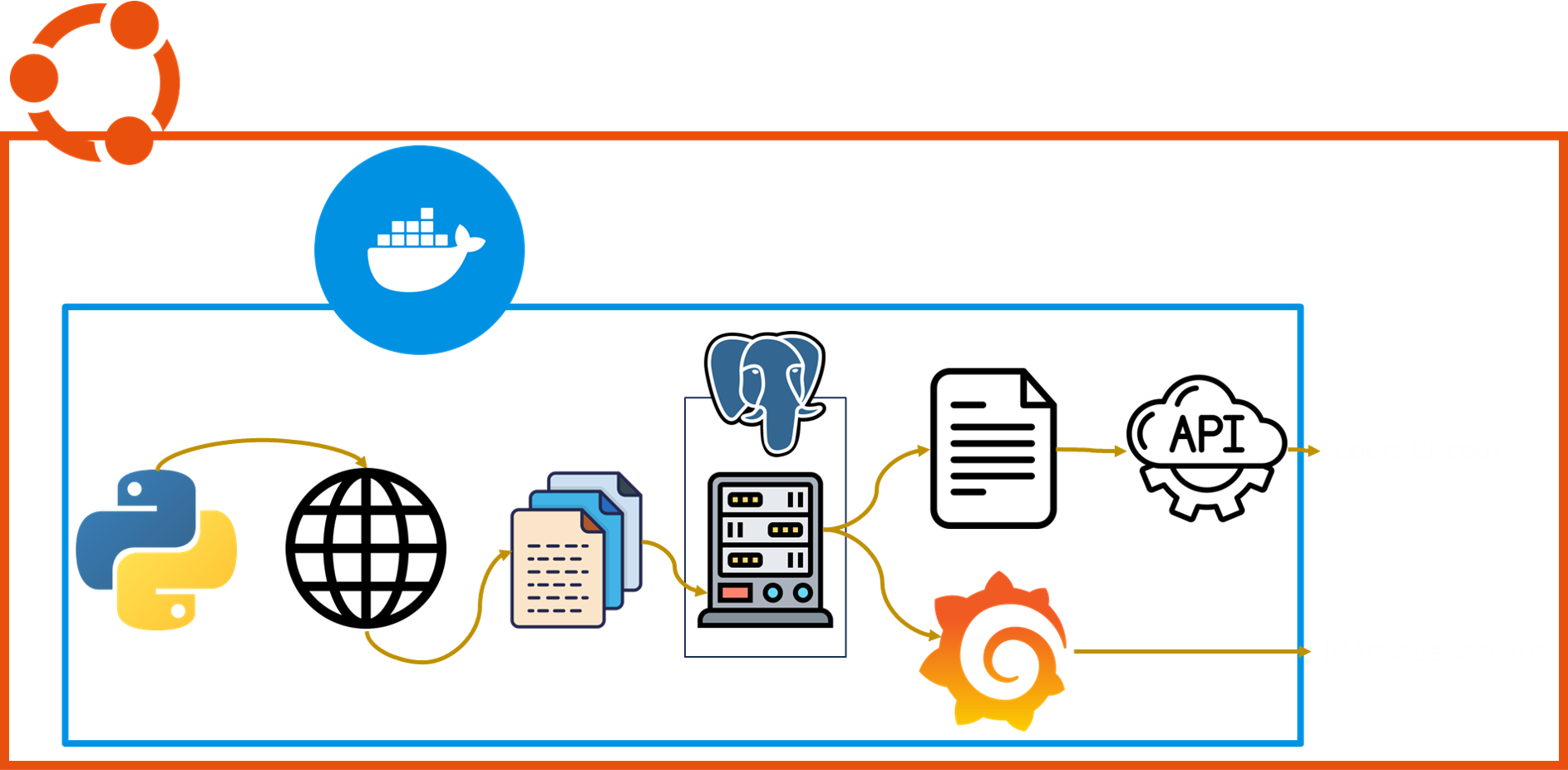
Ubuntu / VPS
Le VPS Ubuntu constitue la couche principale du projet. Il fournit les ressources machine nécessaires à l’exécution de tous les services, à savoir CPU, mémoire, stockage et réseau.
Docker
Docker organise le projet en services distincts. Chaque composant tourne dans son conteneur, ce qui facilite le déploiement, la maintenance et l’isolation des rôles techniques.
Python / Ingestion
Les scripts Python récupèrent les données de marché depuis Internet. Ils assurent la collecte, la mise en forme et l’insertion des données dans la base PostgreSQL.
PostgreSQL
PostgreSQL est la base centrale du projet. Les données collectées y sont stockées, organisées et agrégées afin d’être exploitées ensuite par l’API et les dashboards.
API FastAPI
L’API FastAPI fait le lien entre la base de données et le site web. Elle transforme les requêtes du frontend en réponses structurées contenant les séries temporelles et les indicateurs nécessaires aux graphiques.
Site web
Le site constitue la couche finale de restitution. Il récupère les données depuis l’API et les affiche sous forme de dashboards interactifs pour permettre une lecture plus claire du marché.
Prometheus
Prometheus collecte les métriques techniques du serveur et de certains services. Il permet de conserver un historique de surveillance du système.
Grafana
Grafana exploite les métriques collectées par Prometheus pour les afficher sous forme de dashboards de supervision, par exemple sur la mémoire, le disque, les processus ou la pression système.
Flux principal des données
Internet / Binance → Python ingestion → PostgreSQL → FastAPI → site web / dashboard BTC
Flux de monitoring
Services / serveur → Prometheus → Grafana → dashboards de supervision serveur
Étapes du pipeline data
1. Collecte
Les données de marché sont récupérées automatiquement à partir des API externes.
2. Stockage
Les données brutes et agrégées sont stockées dans PostgreSQL.
3. Exposition
Une API FastAPI fournit les séries temporelles et indicateurs au site.
4. Visualisation
Les résultats sont affichés dans les dashboards marché et monitoring.
Tables principales
Le stockage repose sur des tables contenant les bougies de marché, les trades et les agrégations construites pour accélérer certaines lectures. Cela permet de garder à la fois un niveau fin d’information et une bonne performance d’affichage.
Logique d’agrégation
Les données très fines sont utiles pour certains graphiques, mais trop coûteuses pour d’autres. Des agrégations horaires ont donc été introduites afin de conserver les indicateurs importants tout en réduisant le temps de chargement.
Pistes d’amélioration
Indicateurs supplémentaires
Ajouter de nouveaux indicateurs techniques, enrichir la lecture du marché et étendre l’analyse à d’autres actifs ou à d’autres horizons temporels.
Alerting
Mettre en place un système d’alertes sur les métriques serveur ou sur certains seuils de marché pour améliorer la réactivité du système.
Sécurisation de l’infrastructure
Mieux séparer les services internes des services publics, limiter l’exposition directe des composants techniques et mieux contrôler l’accès aux outils de supervision.
Industrialisation
Ajouter tests, CI/CD, meilleure automatisation du déploiement et surveillance plus avancée pour rapprocher davantage le projet d’une mini-plateforme de production.